

こんにちは!
たぬきけいばです!
うちのたぬき、競馬予想AIの作り方をふんわりとご紹介してみます!
うちは競馬予想ブログなんですが、このページの閲覧数がやたら多いです。。。
皆さんそれだけ競馬予想AIの開発に興味がある、ということなんでしょうね。
「これから競馬予想AIを作ってみたい!」と考えている方の参考になれば嬉しいですが、細かい作り方はそういうブログやYouTubeあたりで探してみることをおすすめします。
ここでは「へーこんな感じで予想してるんだ!」という雰囲気をお伝えできたら嬉しいなーと思います。
あくまで私の場合なので、全然参考にならないかもしれませんが、、、
それでは早速紹介していきますね!
競馬予想AI制作に関する前置き
競馬予想AIの開発はめちゃめちゃ面白いです。
「こんな要素重要じゃないかな?」と思いついたことを実装して、テストしてみて、少しずつAIを賢くしていきます。
自分で作ったAIを実戦に投入し、競馬を予想してくれるだけで感動、もし的中でもしたらもう最高です。
とにかく自分のAIがかわいくて、競馬が以前よりも楽しくなりました。
反面、競馬予想AIの開発にはとにかく時間がかかります。
加えて、開発は全く華々しいものではなく、とても泥臭い作業です。
プログラミングに詳しくない人であれば、最低限の勉強も必要でしょう。
この「最低限の勉強」のハードルがとても高く、競馬予想AIに興味があっても諦めてしまう人が多いのではないかと思っています。
でも、競馬予想AIの開発にプログラミングを完璧にマスターする必要なんてないんです。
競馬予想AIに必要な内容だけ、必要の都度勉強すればOKです。
分厚い参考書を買って全部覚えるような必要はありません。
プロのプログラマーでも「あれ?ここってどういうふうに書くんだっけ?」とネットで検索しながらプログラムを書くんです。
また、プログラミングはエラーとの闘いです。
発生するエラーにひとつひとつ対処して、エラーを減らしていきながら形にしていきます。
これもプロのプログラマーも同じです。
プロと初心者で違うのはエラーが起きる頻度と発生したエラーの対処にかかる時間です。
誰だって最初は初心者なんです。
プログラミングを始める・続けるのに必要なのは熱量と根気だけだと思っています。
プログラミングでできることが増えてくるとどんどん楽しくなっていきますよ!
競馬予想AIを作るために必要なもの
必要なものはほとんどありません。
パソコンとインターネット環境くらいでしょうか。
うちのたぬちゃんくらいのAIであれば、パソコンも何十万円もするようなものでなくて大丈夫です。
私はずっとパソコンはデスクトップ派でしたが、4年前くらいにMacBook Airを買って以降、ほぼ競馬予想AIの専用機として使い続けています。
MacBook Proですらありませんが、それでもスペック的に全然問題ありません。
もちろんOSはWindowsでも大丈夫です。
少し昔はWindowsよりもMacの方が開発環境が構築しやすい、というメリットがあったんですが、最近はWindowsでも簡単に環境構築できるので、OSは好みで大丈夫です。
Linuxでも良いですよ。
パソコンにはデスクトップとノート(ラップトップ)がありますが、もし新しく買うのであればおすすめは断然ノートです。
同じ価格なら比較的性能が良く、後から拡張がしやすいのもデスクトップですが、AI開発はとにかく試して試して試して…の繰り返しです。
開発を身近に感じるためにも、場所を選ばず使えるノートが個人的にはおすすめです。
また、私は「python」というプログラミング言語を使ってたぬきの開発をしています。
プログラミング言語は色々あってそれぞれ特徴があるのですが、現状AIの開発ならpython一択、というレベルでpythonが支持されています。
他にもC++やR、JavaScriptといった言語あたりもAI開発で人気があります。
もしこれまでに触ったことがある言語があれば、それを選んでみるのも良いかと思います。
ちなみに各プログラミング言語はインターネット環境さえあれば無料で使用することができます。
開発環境の構築は少し面倒なものもあるので、他のサイトさんを参考にしてください。
一応pythonの本を紹介しておきますが、これは買わなくても大丈夫です!
理由は基本的に全部ネットで検索できるからです。
本を買う主な理由は「言語を体系的に学べるから」、「手元にあればいちいち検索しなくても良いから」です。
決して本の内容を覚える必要はありません。
ふと書き方を忘れた時なんかに「たしか本のあのへんに書いてたな」と思い出すことができれば十分です。
本が手元にあった方がプログラミングがはかどる、という人もいるので参考までに。

この本を制作しているオライリー社はプログラミング等の教育書籍で世界的に有名な企業で、特にこのpython入門本はいろんなとこで紹介されてます。
私も実際に持ってますが、pythonを体系的に学ぶにはとても良い参考書だと思います。
実は私、「本なんか買う必要ない!」と言った割に、競馬予想AIを作るにあたって結構いろんな本を買って読みました。
機会があればおすすめの本の紹介もしたいです。
2024.10.23 参考書紹介の記事を書きました!👇👇

競馬予想AIの動作
かなりざっくりですが、競馬予想AIは以下のような流れで動作します。
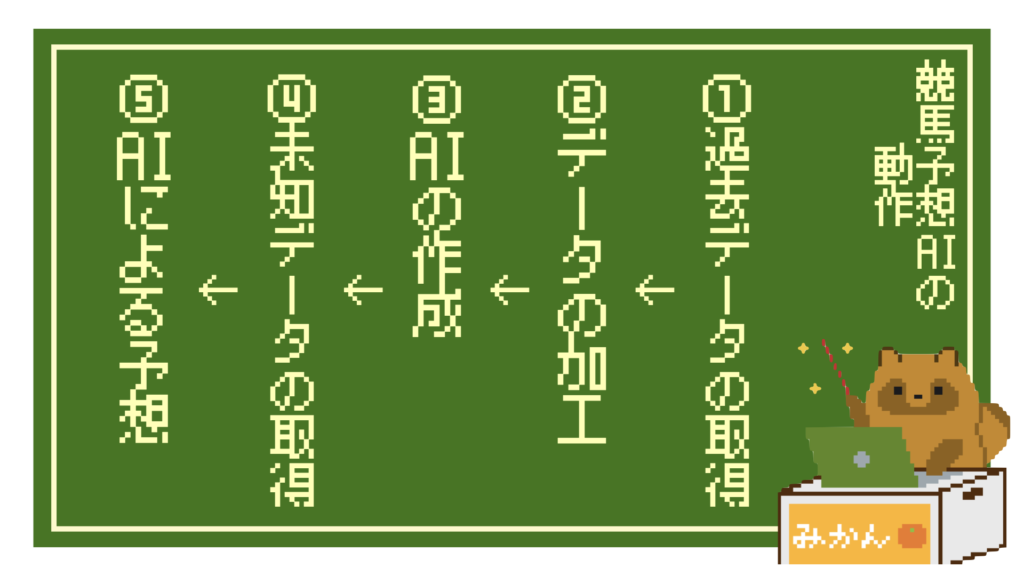
それぞれについて解説していきますね!
①過去データの取得
まずは過去データの取得です。
データが無いことには何も始まりません。
データの取得にはいくつか方法があります。
メジャーなのはJRA-VANやJRDBといった競馬情報サイトに有料登録してデータをダウンロードする方法でしょうか。
必要なデータをすぐに集めたい場合にはとても有効ですが、JRA-VANはMacに対応していない、という落とし穴もあります。
JRDBはサイトやデータの構造が独特で、少し悩むこともあるかと思いますが、扱っている情報量はとても多いです。
もうひとつは特定の競馬情報サイトからデータを取得する方法です。
こちらはお金がかからない代わりに時間がかかります。
タダならこっち一択じゃない?
と思うかもしれませんが、例えば中央競馬1年分の過去データを取得するとなれば、約3,000レース分のデータを地道にサイトからコピーしてくる必要があります。
1ページのコピーに1分かかるとしたら50時間くらいかかるってこと・・・?
さすがに無理ですよね。
そこで、スクレイピングやクローリングという技術を使ってサイトの自動巡回プログラムを作ります。
プログラムは高速で動作させることが可能ですが、あまりに早過ぎてサイトに負荷を与えてしまう可能性があります。
そのため、わざとゆっくり間隔をかけてプログラムを動作させます。
その結果思ったよりも時間はかかりますが、プログラムが動いている間、人間は何もする必要がないので楽です。
寝ている間にプログラムを動かしてデータをとってきてもらう、みたいなことが可能です。
プログラムを作ったり動いてる間待ったりと少し面倒ですが、スクレイピング・クローリングの知識は持っておいて損はないと思います。
そんな面倒なこと無理!
競馬予想AIの開発以外のことはやりたくない!
そういう人はデータを買いましょう。
圧倒的にそちらの方が早いです。
今「競馬予想AIを作りたい欲」があるのであれば、さっさとデータを手に入れてしまい、作り始めるのが得策かもしれません。
このあたりは好みになるかと思います。
②データの加工
次にデータの加工です。
ここがAI開発のメインと言っても過言ではありません。
時間もめちゃくちゃかかります。
例として、私は以下のようなデータを作成しています。
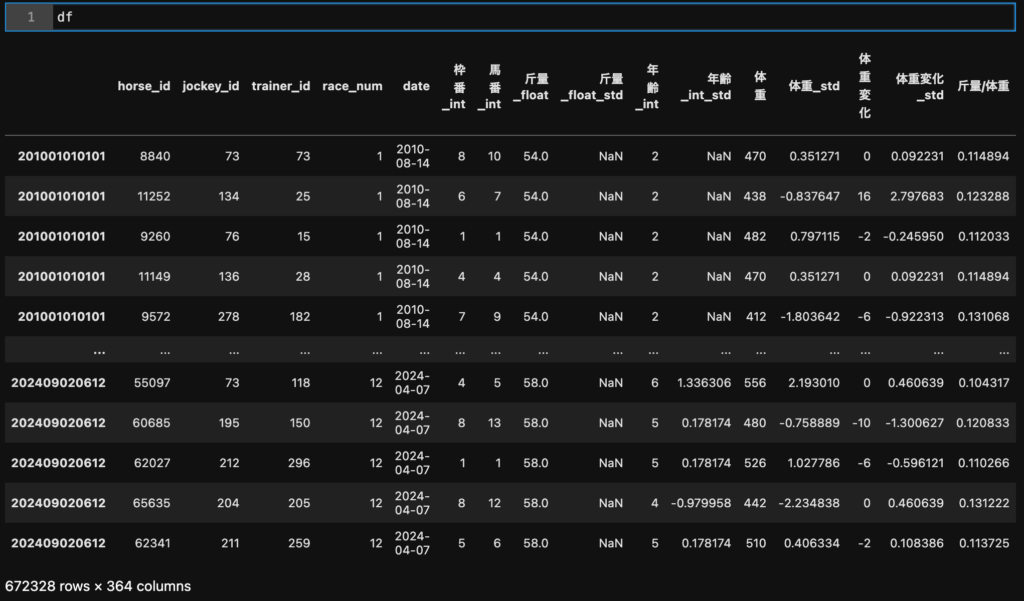
普通にエクセルで作れそうなデータですが、下の方に表示されているとおり約67万行、360列というとても大きなデータです。(ちなみにこれは一部です。。。)
1行1行があるレース時点での1頭の馬を表しています。
なので複数のレースを走った馬は何回か行に登場します。
これはあくまで私の場合で、人によっては1行でひとつのレース全体を表していたり、レースごとにデータ(ファイル)を分けていたり、といった違いもあると思いますが、なんとなくこんなデータを作っている、というイメージができればOKです。
少し脱線しましたが、ここでは取得したデータをAIが読み込める「キレイなデータ」にすることが目的です。
キレイなデータってどういう意味??
「誰が見ても誤解のないデータ」のようなイメージです。
AIは数値を扱います。
数値ということは、1と2なら1の方が小さい、450と500なら500の方が大きい、という比較することができます。
例えば、過去のデータからある馬のこれまでの着順のデータをAIに与えたいとします。
着順には基本的に1から出走頭数(最大18)までの数値が入りますが、稀にレース途中での中止等により数値が入っていない場合もあります。
(中止の場合はよく着順結果に「中」という漢字が入ったりしますよね。)
AIは着順全てを数値として扱いたいのに、着順の中に漢字が入っていると数値同士の比較ができず、エラーとなってしまうんですね。
なので、こういったイレギュラーなデータを「0」や「999」といった通常ではあり得ない値で置き換えたり、平均値を入れたり、時には欠損値として値を持たせないよう処理します。
こうやって「キレイなデータ」を作っていきます。
また、例えば天候や馬場状態など、元々のデータが数値でないような要素もあります。
天候なら晴れを0、曇りを1、小雨を2、雨を3、小雪を4、雪を5みたいにしたらどう?
賢い方はこんなふうに考えるかもしれません。
しかし、これは半分正解で半分間違いです。
事実、さきほどのたぬの発言のようにすればAIは作れてしまいます。
ですが、正しく認識できてはいません。
先に書いたとおり「数値は比較できてしまう」んです。
つまり、AIは数値が大きければ大きいほど雪に近く、小さければ小さいほど晴れに近くなる、と学習します。
これは、雨の先に雪があることを意味します。
実際には雨が雪になるかどうかは気温が影響していて、雨がひどくなれば雪になる、ということはないですよね?
通常、AIは数値同士の関係性を学んでしまうので、このやり方では正しくAIが天候を認識してくれないんです。
ではどうするかというと、以下のようにしてしまいます。

↑↑これを
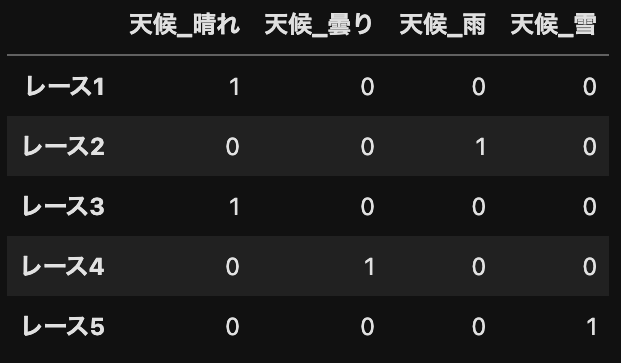
↑↑こうします。
値は0か1しか入りません。
「晴れかどうか」、「曇りかどうか」といった項目全てに対して〇×で答えを表すイメージです。
こうすれば列は増えますが、天候の状態を完全に分離して表現できます。
この手法を専門用語だとone-hot-encodingと言ったりします。
もしくはAIに「これは数値ではないよ、カテゴリーを表すただの数字だよ」と念押しして与えてあげることで、「晴れを0、曇りを1、雨を2、雪を3」みたいに扱うという方法もあります。
これは専門用語だとlabel-encodingと言ったりします。
同じことを表現しているのですが、AIの精度には若干の差が生じます。
どっちを使えばいいのか迷いますが、これは実際に試してみないとわかりません。
こんなふうに、人間が読むことを想定されたデータをAIが読めるようにキレイにしていくのがデータの加工です。
また、このタイミングで「前走の着順は予想に影響しそうだな」とか「いやいや過去5走の平均着順の方が影響しそうだな」とか「どっちも入れてみよう!」といったように色々思いついたことを試しながら、データ(「特徴量」と言います。)を追加していきます。
AIの出来/不出来の差は主にここで生じます。
面白いことに、逆にここで除外した方が良いデータなんかもあるんですよね。
代表的なもので言うとかなり前の世代の血統情報なんかです。
4世代や5世代上の情報になると、おそらく予想にほぼ影響を与えず、逆にノイズのようになってしまうのではと考えています。
この特徴量を追加したり削除したりする工程を特徴量エンジニアリングと言ったりします。
そして、AIの出来がここで決まるとも書いたとおり、ここが腕の見せ所であり、AIの差別化が図られる部分です。
おそらく、私を含めてほぼ全てのAI予想家さんが「自分だけが知っている、皆に教えたくない良い特徴量」を持っているものと考えています。
そんなのどうやって作るの?
こればっかりは色々試してみるしかありません。
特徴量と特徴量を組み合わせてみる等、計算で作ることもあれば、実は以外なところが結構な影響を与えていて、偶然それを見つける、といったこともあります。
「ある街の犯罪数を予測するためのAIを作っていたが、頑張って考えた特徴量よりも冗談で入れてみた月の満ち欠けのデータの方が有効だった」みたいな笑い話も聞いたことがあります。
(実際相関関係があるのかはわかりません。。。)
それくらい色々なことを試す必要があるんです。
私が公開できる範囲で割と精度に影響したな、と思っているのは「前回出走からの日数」とかでしょうか。
理由はよくわかりませんが、調子の良い時のローテ間隔とかそういうのを評価してるんでしょうか。
面白いですよね。
こういったことをどんどん試していきます。
③AIの作成
長くなってきましたが、次はいよいよAIの作成です。
モデルの作成、と言ったりします。
実はモデルの作成自体は簡単です。
競馬予想AIと言っても、すべてをイチから作る人はほとんどいません。
多くの人は、既に確立されているアルゴリズムにタダ乗りしているだけです。
よく耳にするディープラーニングなんかも、データの加工の段階でディープラーニングができる状態にキレイに加工さえすれば、
「ディープラーニングを使う!」
という意味の数行のプログラムを書けば、ディープラーニングを使ったAI学習ができてしまいます。
実際にディープラーニングを実行するのに必要なプログラム(ほぼ数式です)を全部1人で書くとなれば数百行以上のプログラムが必要ですが、この長いプログラム部分は「部品」として簡単に他のプログラムから呼び出せるようになっているんですね。
モデルの作成で他に気をつけるポイントはないの?
あります。
AIを作る上で最も大事なのは「何を解くか」をちゃんと設定することです。
競馬を予想するにあたり、解くべき問題は一意ではありません。
「AIに何を解かせたいか」は自分で設定する必要があります。
例えば、一番に考えるのは「各馬が1着になる確率」あたりでしょうか。
しかし、「各馬の予想走破タイム」や「各馬が3着以内に入る確率」、もしくは「各馬が掲示板に入らない確率」みたいな問題を設定すると更に良い結果が得られるかもしれません。
問題の設定は先ほどの特徴量エンジニアリングと同じく、色々試してみるしかありません。
AI開発が泥臭いと言ったのはこのあたりの試行錯誤があるためです。
また、どのアルゴリズムを使うか、という問題もあります。
例えば、上に例として書いたディープラーニングは高い精度の代わりに膨大な計算時間が必要です。
普通のパソコンだとモデルの作成に数時間・数日かかる、といったこともザラです。
作って直してを繰り返すAI開発において、時間がかかるというのは大きなデメリットです。
そこで、うちのたぬきはLightGBMというアルゴリズムを採用しています。
Light(軽い)と言うように、とても動作が軽く、計算時間がとても短い割に、比較的高い精度を出すことができます。
たぬきの例だとだいたい2~3分で学習が完了します。
(データの加工にはめちゃめちゃ時間がかかるんですけどね…)
他にもいろいろなアルゴリズムがあるので、それぞれの競馬予想AIがどんなアルゴリズムを採用しているのか、気にしてみても面白いかもしれません。
少し話が逸れましたが、AIの作成に必要なデータはこんな感じのデータです。
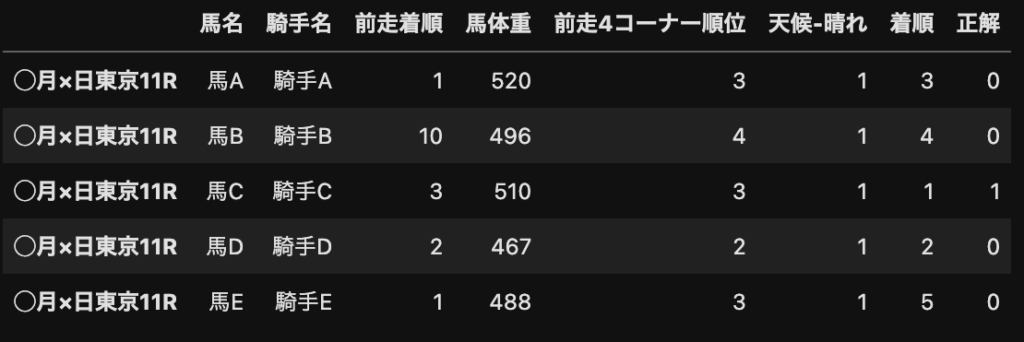
一番右の「正解」ってなに??
今回はAIに「各馬が1着になる確率」を当てさせようとしているので、1着を正解(1)、1着以外を全て不正解(0)とした「正解」という列を作っています。
ちなみに、この「正解」の列を「目的変数」と呼び、この目的変数を予想するために使うその他全ての列を「説明変数」と呼んだりします。
たくさんの説明変数からひとつの目的変数を求めるイメージです。
このデータからAIを作るのですが、実はその際にひと工夫必要です。
具体的には、さっきのデータをあらかじめ4つに分割する必要があります。
どうやって分けるの?
こんな感じです。
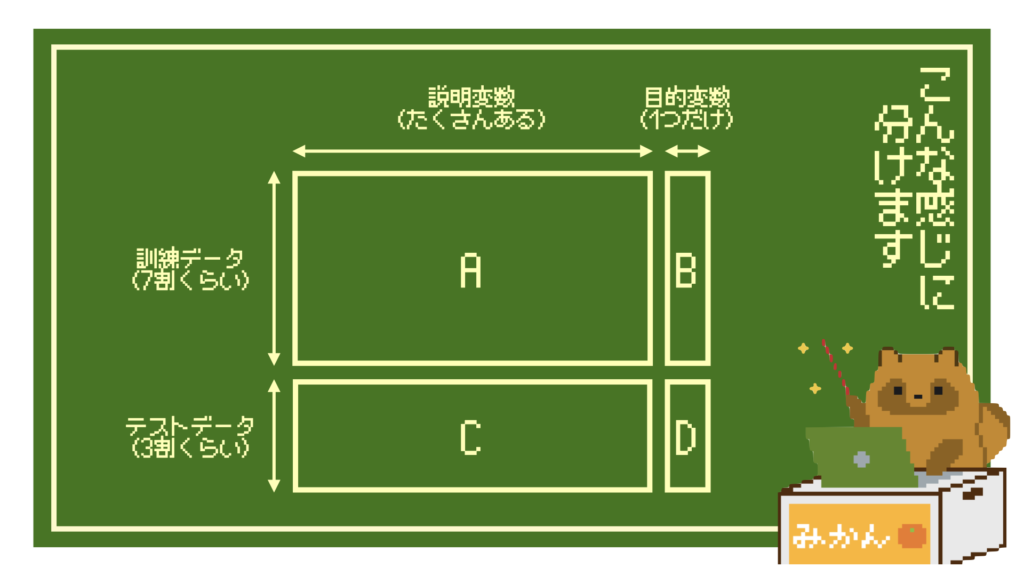
これはAIモデルを作り、さらにその後でそのモデルを評価するための分割イメージです。
まず、データ全体はさっきのとおり説明変数(A・C)と目的変数(B・D)に分かれています。
説明変数は馬体重や前走の着順など、予想するためのデータであり、目的変数は解くべき答えのデータでしたよね。
これをさらに、「訓練データ(A・B)」と「テストデータ(C・D)」に分けます。
データは上から下にかけて時系列的に新しいものが入っています。
そのため、テストデータは訓練データよりも新しいデータになります。
古いデータで訓練して、新しいデータでテストするイメージです。
これはだいたい7:3くらいで分けることが多いです。
こんな感じで4分割して与えてあげると、まず訓練データのAとBで
前走の着順が良いほど今回の着順も良さそう
体重はこれくらいが一番勝率が高そう
みたいなことを説明変数と目的変数を突き合わせながら勝手に学んでくれて、AIのモデルが作られます。
そして、そのモデルが未知のデータに対してどの程度正しい振る舞いができるかをテストデータのCとDで確認します。
AIモデルにはC(説明変数)だけを与えて、各馬が1着になるかどうかを予想させます。
そして、最後にAIの予想結果とD(目的変数)の答えを突き合わせて、どの程度合っていたかをチェックします。
ここでひとつ大きなポイントがあります。
以下の画像は先ほども触れたAIに与えるデータの例です。
さっきはあえて触れませんでしたが、下の画像のようなデータをそのままAIに与えてしまうと、AIは100%1着の馬を当てることができてしまいます。
なぜでしょうか?
答えは「説明変数に着順の情報があるから」です!
AIは賢いので、着順が「1」であれば正解が「1」であることを学習します。
問題の中に答えがあるようなイメージです。
これではAIは求めている動きをしてくれないので、問題(説明変数)の中から直接答え(目的変数)につながってしまうものは削除しておく必要があります。
正しくはこういうデータにする必要があります。(「着順」の列を削除しました。)
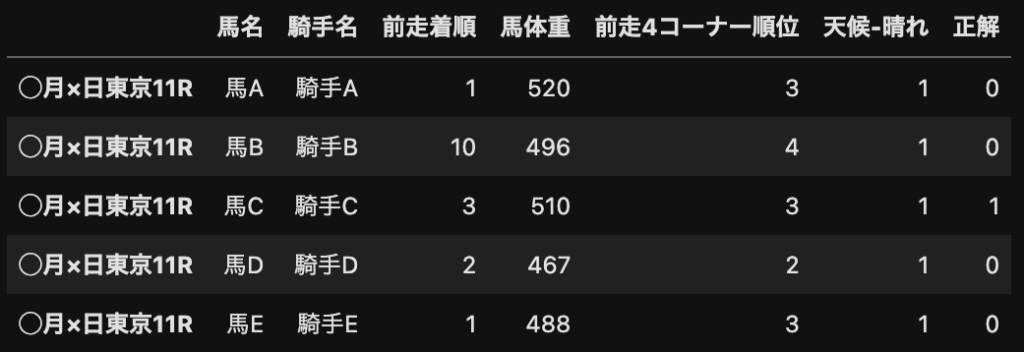
今回は簡単な例を出しましたが、「獲得賞金」なんかもNGです。
過去のデータだと着順はもちろん、その着順によって得た賞金もデータとして入っている場合があります。
着順のデータをちゃんと消しても、AIは獲得賞金の情報を見て、「各レースで一番大きな賞金を得ている馬が1着になっている」と学習します。
このように、問題の中から直接正解につながる情報がないかは注意して見ておいてください。
なんとなくこんな流れになります。
AI開発ってなんかすごいことやってそう!と思うかもですが、さっきも書いたとおり、データさえ作って与えてあげればAIは勝手に作られます。
この後少しだけ小難しいパラメータの調整なんかがあったりしますが、大切なのは「とにかくどうやって質の良いデータを準備するか」なんです。
④未知データの取得・⑤AIによる予想
AIモデルが完成したら、いよいよ予想をしていきましょう!
・・・と言っても、ほぼさっきのモデルの作成とやることは変わりません。
テストデータに未知のデータ(これから走るレースのデータ)を与えてあげれば良いんです。
訓練データとテストデータは7対3くらい、としていましたが、本番では訓練データが「過去データ全て」、テストデータが「未知データ」、という感じです。
1レースだけ予想するのであれば、未知データに入るのは1レース分のデータだけです。
訓練データとテストデータの比率で言うと10000対1みたいなレベルかもしれません。
未知データはどうやって準備するの?
自分で作っても良いですが、冒頭でお話しした、競馬情報サイト等からの取得が現実的かと思います。
スクレイピング・クローリングの知識があった方が〜と言っていたのはこのためです。
もちろんその場合は競馬情報サイトに過剰にアクセスするといったことがないよう、細心の注意を払ってください。
ここまでくるともうあとは実際に予想するだけです!
未来のレースの予想では当然、目的変数(1着かどうか)はわかりませんが、説明変数(馬名や騎手名、前走の着順等)はわかりますよね?
モデルには説明変数のみを渡してあげます。
するとモデルが説明変数から計算した目的変数(予想)を出力してくれる、というイメージです。
これであなたもAI予想家!
もちろんそうなのですが、大変なのはここからです。
モデルには当然良し悪しがあり、さらに性能を上げていく必要があります。
先に書いたように、特徴量エンジニアリングを何回も繰り返し、少しずつAIを賢くしていきます。
これが面白いのですが途方もない作業になります、、、
しかし、だんだんとAIが賢くなってくると愛着も沸きますし、どんどん楽しくなってきますよ!
ここからは競馬予想AIとは直接関係ない部分ですが、うちのたぬきであれば予想結果から各馬の偏差値を計算し、画像を作成します。
その画像をブログにアップし、Xで告知するまで、すべて自動で行います。
こんなのも全部pythonで実現できます。
正直いきなりここまで自動化するのは大変なので、徐々に必要な部分を自動化していけば良いと思います。
以上、長くなりましたがだいたいこんな感じで競馬予想AIは作られています!
最後に
ここまでざっくりと競馬予想AIの作り方や動作について概要をご説明してきました。
AI開発は以外と簡単な反面、精度を上げようと思うと泥臭く、地味な作業であると理解して貰えると7割くらい合ってると思います笑
しかしAI開発はとても面白く、AI以外のデータ処理等の知識も身に付きますので、手を出してみて損をすることはないと思っています。
何より、「自分だけのAIを自分で作る」という達成感や満足感はとても大きいです。
興味を持たれた方はぜひ挑戦してみてください。
有効な特徴量を自分なりに整理することで、もしかすると競馬予想自体の上達に繋がったりする可能性もあります。
今までとは違った競馬の楽しみが見つかるかもしれませんよ!
今後は気が向いたら競馬AIの特徴量の考察なんかもしていきたいと考えています。
それではまた!


コメント